



Большие языковые модели (LLM) – это передовые модели искусственного интеллекта, использующие методы глубокого обучения, в том числе подмножество нейронных сетей, известных как трансформаторы. LLM используют трансформаторы для выполнения задач обработки естественного языка (NLP), таких как перевод языка, классификация текстов, анализ настроения, генерация текстов и ответы на вопросы.
LLM обучаются на огромном количестве наборов данных из самых разных источников. Это характеризует их огромный размер – некоторые из наиболее успешных LLM имеют сотни миллиардов параметров.
Почему большие языковые модели важны?
Достижения в области искусственного интеллекта и генеративного ИИ расширяют границы того, что мы когда-то считали надуманным в компьютерном секторе. LLM обучаются на сотнях миллиардов параметров и используются для решения проблем, связанных с человекоподобным взаимодействием с машинами.
LLM полезны для решения проблем и помощи бизнесу в решении коммуникационных задач, поскольку они используются для генерации человекоподобного текста, что делает их неоценимыми для таких задач, как резюмирование текста, перевод языка, генерация контента и анализ настроения.
Большие языковые модели сокращают разрыв между человеческим общением и машинным пониманием. Помимо технологической отрасли, применение LLM можно найти и в других областях, таких как здравоохранение и наука, где они используются для решения таких задач, как экспрессия генов и разработка белков. Языковые модели ДНК (геномные или нуклеотидные языковые модели) также могут использоваться для выявления статистических закономерностей в последовательностях ДНК. LLM также используются для обслуживания клиентов/функций поддержки, таких как чат-боты AI или разговорный AI.
Как работают большие языковые модели?
Чтобы LLM работала с высокой точностью, ее сначала обучают на большом объеме данных, часто называемом корпусом данных. Обычно LLM обучают как на неструктурированных, так и на структурированных данных, прежде чем приступить к процессу преобразования нейронной сети.
После предварительного обучения на большом корпусе текстов модель может быть отлажена для решения конкретных задач путем обучения на меньшем наборе данных, связанных с этой задачей. Обучение LLM в основном осуществляется с помощью неконтролируемого, полуконтролируемого или самоконтролируемого обучения.
Большие языковые модели строятся на основе алгоритмов глубокого обучения, называемых нейронными сетями-трансформерами, которые учатся контексту и пониманию через последовательный анализ данных. Концепция трансформера была представлена в 2017 году в статье “Attention Is All You Need” (“Внимание – это все, что вам нужно”) Ашиша Васвани, Ноама Шазира, Ники Пармара и еще пяти авторов. Модель трансформера использует структуру кодировщика-декодировщика; она кодирует входной сигнал и декодирует его, чтобы получить предсказание на выходе. Следующие графики взяты из их статьи:
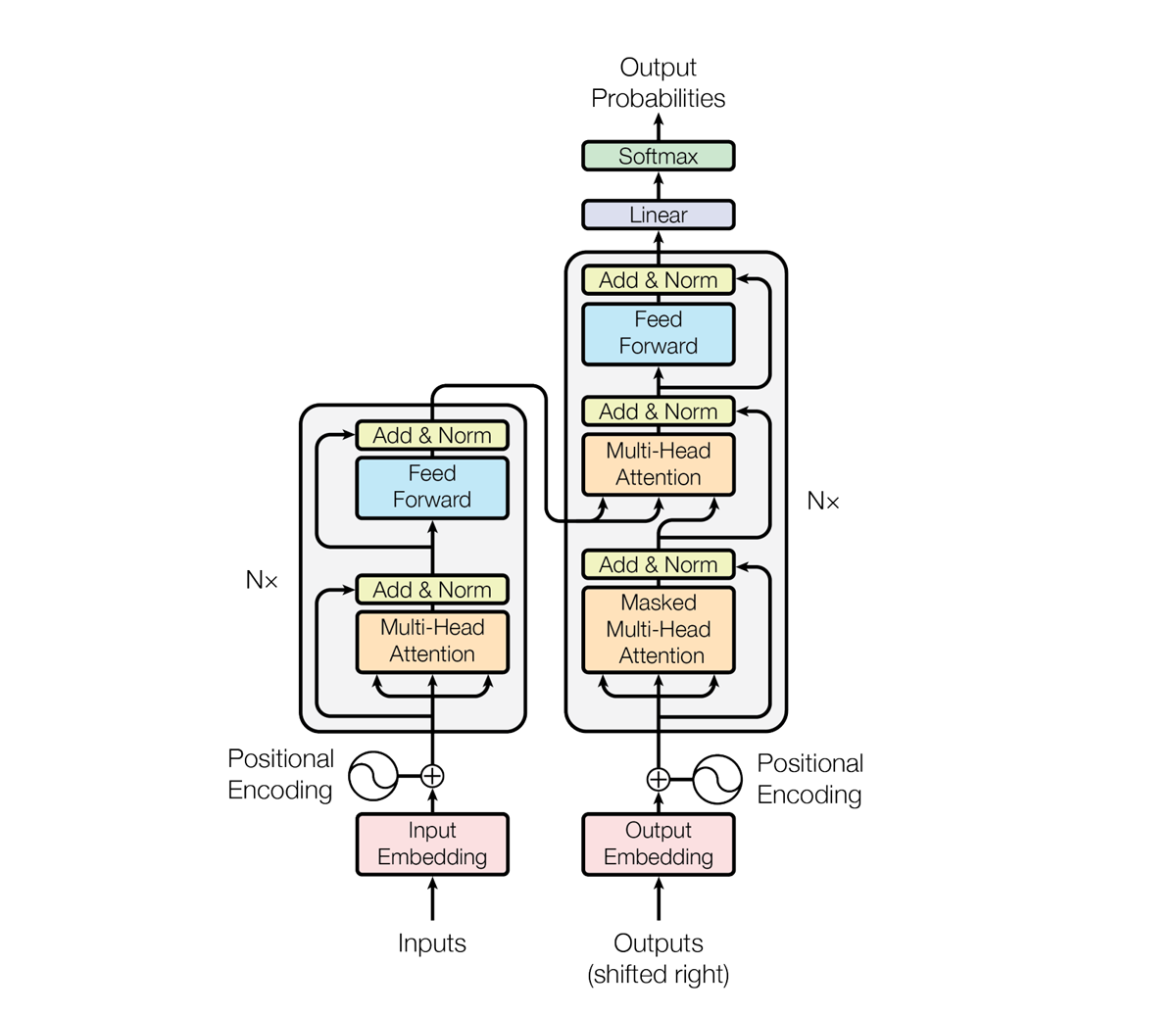
Рисунок 1: Трансформер – архитектура модели. Attention Is All You Need
Multi-head self-attention- еще один ключевой компонент архитектуры Transformer, который позволяет модели оценивать важность различных лексем на входе при составлении прогнозов для конкретной лексемы. Аспект “Multi-head” позволяет модели изучать различные отношения между лексемами на разных позициях и уровнях абстракции.
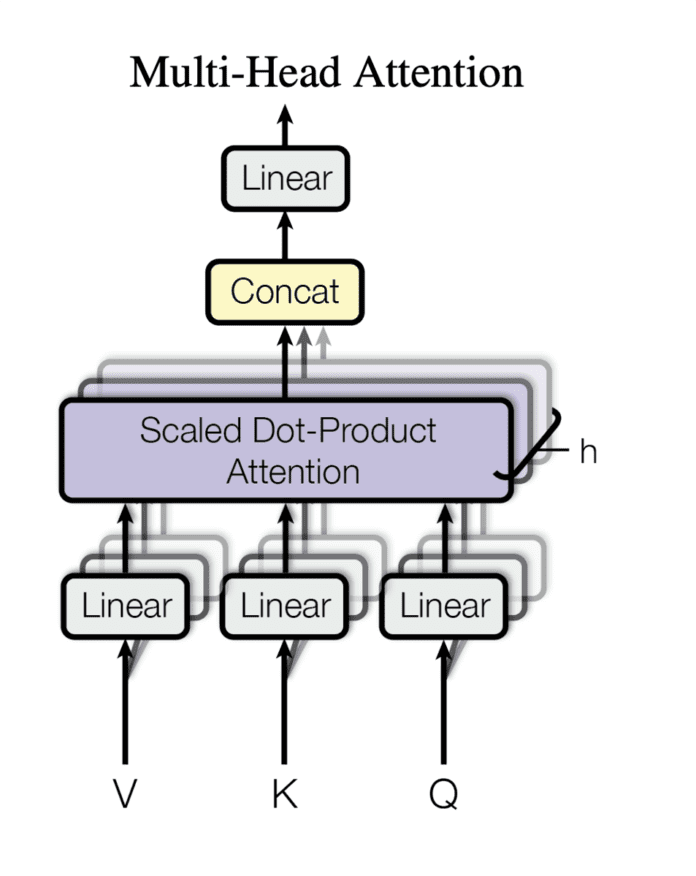
Рисунок 2: Multi-Head Attention –- Attention Is All You Need
4 типа больших языковых моделей
Распространенными типами LLM являются следующие:
Модель представления языка
Многие приложения NLP построены на моделях представления языка (LRM), предназначенных для понимания и генерации человеческого языка. Примерами таких моделей являются модели GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers) и RoBERTa. Эти модели предварительно обучаются на массивных текстовых корпорациях и могут быть точно настроены для решения конкретных задач, таких как классификация текстов и генерация языка.
Модель Zero-Shot
Модели Zero-shot известны своей способностью выполнять задачи без специальных обучающих данных. Эти модели могут обобщать и делать предсказания или генерировать текст для задач, с которыми они никогда не сталкивались. GPT-3 является примером модели с нулевым результатом – она может отвечать на вопросы, переводить языки и выполнять различные задачи с минимальной тонкой настройкой.
Мультимодальная модель
Изначально LLM были разработаны для работы с текстовым контентом. Однако мультимодальные модели работают как с текстовыми, так и с графическими данными. Эти модели предназначены для понимания и генерирования контента в различных модальностях. Например, CLIP от OpenAI – это мультимодальная модель, которая может ассоциировать текст с изображениями и наоборот, что делает ее полезной для таких задач, как создание подписей к изображениям и поиск изображений по тексту.
Fine-Tuned или модели, специфичные для конкретной области
Хотя предварительно обученные модели представления языка универсальны, они не всегда оптимальны для конкретных задач или доменов. Модели, прошедшие тонкую настройку, подвергаются дополнительному обучению на данных, специфичных для конкретного домена, чтобы улучшить свои характеристики в определенных областях. Например, модель GPT-3 может быть отлажена на медицинских данных для создания медицинского чатбота или помощи в медицинской диагностике.
Примеры больших языковых моделей
Вы, возможно, слышали о GPT – благодаря чату ChatGPT buzz, чатботу с генеративным ИИ, запущенному компанией Open AI в 2022 году. Помимо GPT, существуют и другие заслуживающие внимания большие языковые модели.
- Языковая модель Pathways (PaLM): PaLM – это LLM на основе трансформатора с 540 миллиардами параметров, разработанная Google AI. На данный момент PaLM 2 LLM используется в последней версии Google Bard.
- XLNet: XLNet – это авторегрессионный трансформатор, который сочетает в себе двунаправленные возможности BERT и авторегрессионную технологию Transformer-XL для улучшения задачи моделирования языка. Он был разработан исследователями Google Brain и Университета Карнеги-Меллона в 2019 году и может выполнять такие NLP-задачи, как анализ настроения и языковое моделирование.
- BERT: Bidirectional Encoder Representations from Transformers – техника глубокого обучения для NLP, разработанная Google Brain. BERT можно использовать для фильтрации спама и повышения точности функции Smart Reply.
- Генеративные предварительно обученные трансформеры (GPT): разработанный OpenAI, GPT является одной из самых известных больших языковых моделей. Она претерпела различные итерации, включая GPT-3 и GPT-4. Модель может генерировать текст, переводить языки и информативно отвечать на ваши вопросы.
- LLaMA: Large Language Model Meta AI была публично выпущена в феврале 2023 года с четырьмя размерами модели: 7, 13, 33 и 65 миллиардов параметров. В июле 2023 года Meta AI выпустила LLaMA 2, доступную в трех версиях, включающих 7, 13 и 70 миллиардов параметров.
7 примеров использования больших языковых моделей
Хотя LLM все еще находятся в стадии разработки, они могут помочь пользователям в решении различных задач и удовлетворить их потребности в различных областях, включая образование, здравоохранение, обслуживание клиентов и развлечения. Некоторые из распространенных целей использования LLM таковы:
- Перевод языка: LLM могут генерировать естественные переводы на несколько языков, позволяя компаниям общаться с партнерами и клиентами на разных языках.
- Генерация кода и текста: Языковые модели могут генерировать фрагменты кода, писать описания продуктов, создавать маркетинговый контент и даже составлять электронные письма.
- Ответы на вопросы: Компании могут использовать LLM в чат-ботах и виртуальных помощниках для мгновенного ответа на вопросы пользователей без участия человека.
- Образование и обучение: Технология может генерировать персонализированные тесты, давать пояснения и обратную связь на основе ответов ученика.
- Обслуживание клиентов: LLM является одной из базовых технологий для чат-ботов на базе ИИ, используемых компаниями для автоматизации обслуживания клиентов в своей организации.
- Юридические исследования и анализ: Языковые модели могут помочь специалистам в области права в изучении и анализе прецедентного права, уставов и юридических документов.
- Научные исследования и открытия: LLM вносят вклад в научные исследования, помогая ученым и исследователям анализировать и обрабатывать большие объемы научной литературы и данных.
4 преимущества больших языковых моделей
LLM обеспечивают огромный потенциал повышения производительности для организаций, что делает их ценным активом для организаций, генерирующих большие объемы данных. Ниже перечислены некоторые преимущества LLM, которые получают компании, использующие его возможности.
Повышение эффективности
Способность LLM понимать человеческий язык делает их пригодными для выполнения повторяющихся или трудоемких задач. В частности, LLM могут генерировать человекоподобный текст гораздо быстрее, чем человек, что делает их полезными для таких задач, как создание контента, написание кода или обобщение больших объемов информации.
Расширенные возможности ответов на вопросы
LLM также можно назвать машиной по генерации ответов. LLM настолько хороши в генерировании точных ответов на запросы пользователей, что экспертам пришлось убеждать пользователей в том, что генеративные ИИ не заменят поисковую систему Google.
Обучение с минимальными затратами или с нулевыми затратами
LLM могут выполнять задачи с минимальным количеством обучающих примеров или вообще без обучения. Они могут обобщать существующие данные, чтобы выводить закономерности и делать прогнозы в новых областях.
Трансферное обучение
LLM служат профессионалам в различных отраслях – их можно тонко настраивать для решения различных задач, что позволяет обучать модель на одной задаче, а затем использовать ее для решения других задач с минимальным дополнительным обучением.
3 проблемы и ограничения больших языковых моделей
Несмотря на то, что LLM обладают множеством преимуществ, у них есть и некоторые существенные недостатки, которые могут повлиять на качество результатов.
Производительность зависит от обучающих данных
Производительность и точность LLM зависят от качества и репрезентативности обучающих данных. LLM хороши лишь настолько, насколько хороши их обучающие данные, а значит, модели, обученные на необъективных или некачественных данных, наверняка дадут сомнительные результаты. Это огромная потенциальная проблема, поскольку она может нанести значительный ущерб, особенно в чувствительных дисциплинах, где точность очень важна, например, в юридических, медицинских или финансовых приложениях.
Отсутствие здравого смысла в рассуждениях
Несмотря на впечатляющие языковые возможности, большие языковые модели часто испытывают трудности с рассуждениями на основе здравого смысла. Человеку присущ здравый смысл – это часть наших природных инстинктов. Но для LLM здравый смысл не совсем обычен, так как они могут выдавать ответы, которые фактически неверны или лишены контекста, что приводит к вводящим в заблуждение или бессмысленным результатам.
Этические проблемы
Использование LLM вызывает этическую обеспокоенность в связи с возможным неправильным использованием или вредоносным применением. Существует риск создания вредного или оскорбительного контента, глубоких подделок (deep fakes) или пародий, которые могут быть использованы для мошенничества или манипуляций.
Основные инструменты больших языковых моделей
- API OpenAI: Компания (OpenAI) предоставляет API, позволяющий разработчикам взаимодействовать со своими LLM. Пользователи могут делать запросы к API, чтобы генерировать текст, отвечать на вопросы и выполнять задачи по переводу языка.
- Hugging Face Transformers: Библиотека Hugging Face Transformers – это библиотека с открытым исходным кодом, предоставляющая предварительно обученные модели для задач НЛП. Она поддерживает такие модели, как GPT-2, GPT-3, BERT и многие другие.
- PyTorch: LLM можно точно настроить с помощью фреймворков глубокого обучения, таких как PyTorch. Например, GPT от OpenAI может быть точно настроен с помощью PyTorch.
- spaCy: spaCy – это библиотека для расширенной обработки естественного языка на Python. Хотя она не может напрямую работать с LLM, она широко используется для решения различных задач НЛП, таких как лингвистически мотивированная токенизация, тегирование частей речи, распознавание именованных сущностей, разбор зависимостей, сегментация предложений, классификация текстов, лемматизация, морфологический анализ и связывание сущностей.
Большие языковые модели в будущем
По мере развития LLM они будут совершенствоваться во всех аспектах. Будущие эволюции смогут генерировать более согласованные ответы, включая улучшенные методы обнаружения предвзятости, смягчения ее последствий и повышения прозрачности, что сделает их надежным и достоверным ресурсом для пользователей в таких отраслях, как финансы, создание контента, здравоохранение и образование.
Кроме того, количество и разнообразие LLM будет гораздо больше, что даст компаниям больше возможностей для выбора оптимального LLM для конкретного внедрения искусственного интеллекта. Кроме того, настройка LLM станет намного проще и более конкретной, что позволит доработать каждую часть программного обеспечения для искусственного интеллекта так, чтобы она работала быстрее и была намного эффективнее и продуктивнее.
Также вероятно (хотя это еще не известно), что большие языковые модели станут значительно дешевле, что позволит небольшим компаниям и даже частным лицам использовать мощь и потенциал LLM.
Итог: Большие языковые модели
Большие языковые модели представляют собой трансформационный скачок в искусственном интеллекте и произвели революцию в промышленности, автоматизировав процессы, связанные с языком.
Универсальность и человекоподобные способности больших языковых моделей к генерации текста меняют способы взаимодействия с технологиями – от чат-ботов и генерации контента до перевода и обобщения. Однако развертывание больших языковых моделей также связано с этическими проблемами, такими как предвзятость обучающих данных, потенциальное нецелевое использование и соображения конфиденциальности при обучении. Чтобы использовать преимущества больших языковых моделей, необходимо сбалансировать их потенциал с ответственным и устойчивым развитием.